BigQueryはブラウザからの操作でテラバイト(TB)、ペタバイト(PB)のデータに対し、SQLを実行できます。
この記事では、登録済みのテラバイトのデータベースに対し、ブラウザからBigQueryでSQLを実行し、検索スピードを体感してみます。
数億レコード規模で公開されている「一般公開データ」にアクセスできるので、大規模でも検索性能を簡単に確認できます。
以下の記事の手順で無料トライアルを申し込むと、実際に動かすことが可能です。
BigQueryの特徴
BigQueryは、ペタバイト規模のデータに対する分析を可能にする、グーグルのクラウドサービスで利用できるフルマネージドのデータウェアハウス(DWH)です。
・数TB~数PBに対するデータに対して、クエリ(SQL)を実行した場合に数秒から数十秒程度で結果が返却される爆速のデータベース
・標準SQLが使用可能。 (SQL 2011規格に準拠)
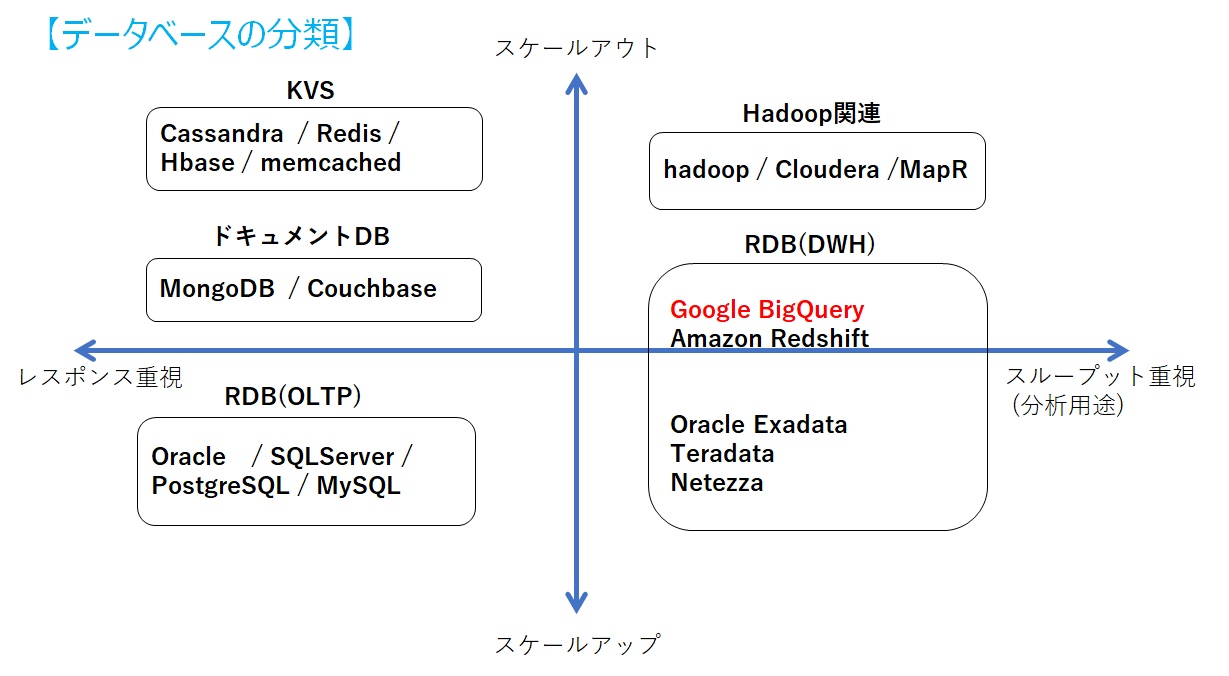
データベースの分類としては以下のような位置付けになります。
BigQueryを使ってみよう
基本的なSQL文を実行して、検索性能を見てみます。
一般公開データを使ってみよう
誰でも利用可能な一般公開データセットという各分野のデータがBigQueryに保存されています。今回、このデータセットを使って検索性能を体感していきます。
一般公開データセットは、毎月、最初の1TB のデータの処理については課金されないため、無料でアクセスできます。
無料枠を超える可能性がある場合は、課金を有効にする必要があります。
(勝手に有料になることはありませんので、無料トライアルで利用している場合も安心して使えます)
BigQueryの一般公開データセット
広告、ビッグデータ、気候、COVID-19(新型コロナ)、経済、教育、金融、医療、機械学習、科学などいろいろな分野のデータが利用できます。
一般公開データセットの使い方
ウェブUI からSQLを実行してみましょう。BigQueryのウェブUI を開きます。
「データ追加」- 「一般公開データセットを調べる」を選択し、”GitHub“で検索します。
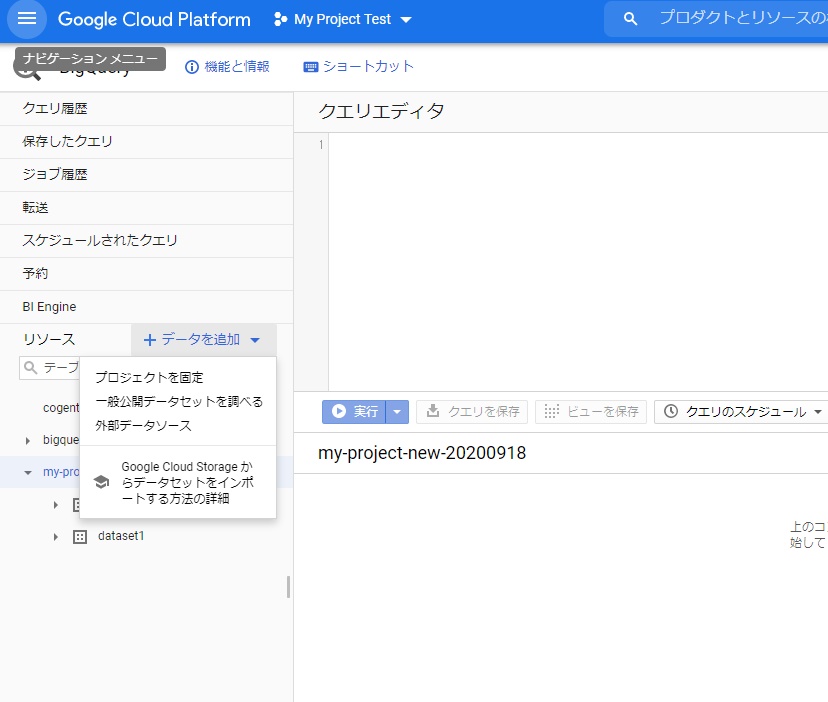
「GitHub Activity Data」を選択し、データセットを表示します。
左の「リソース」に gtihub_repos が表示されたと思います。commits テーブルを利用するので選択します。
[詳細]をクリックし、”表のサイズ”、”行数”を確認します。
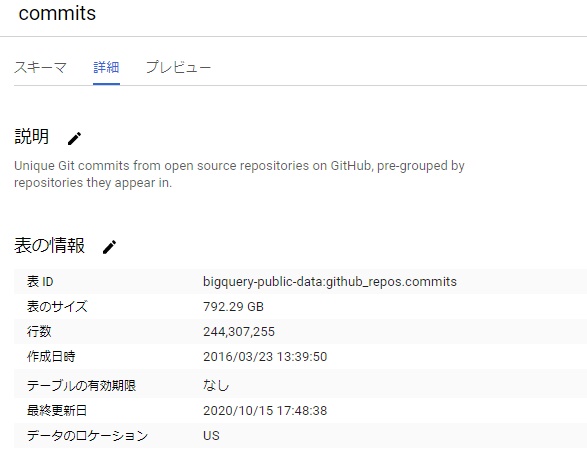
表 : bigquery-public-data:github_repos.commits
表のサイズ: 792.29 GB (約792GB)
行数 : 244,307,255 (約2.4億行)
「テーブルをクエリ」をクリックすると、SQLのひな形が表示されます。
試しに SELECTの後に”*”を入力し、SELECT * とすると「このクエリを実行すると、792.3 GB が処理されます。」と実行前に処理サイズを教えてくれます。
「SELECT * FROM `bigquery-public-data.github_repos.commits` LIMIT 1000」
↓
「SELECT subject FROM `bigquery-public-data.github_repos.commits` LIMIT 1000」
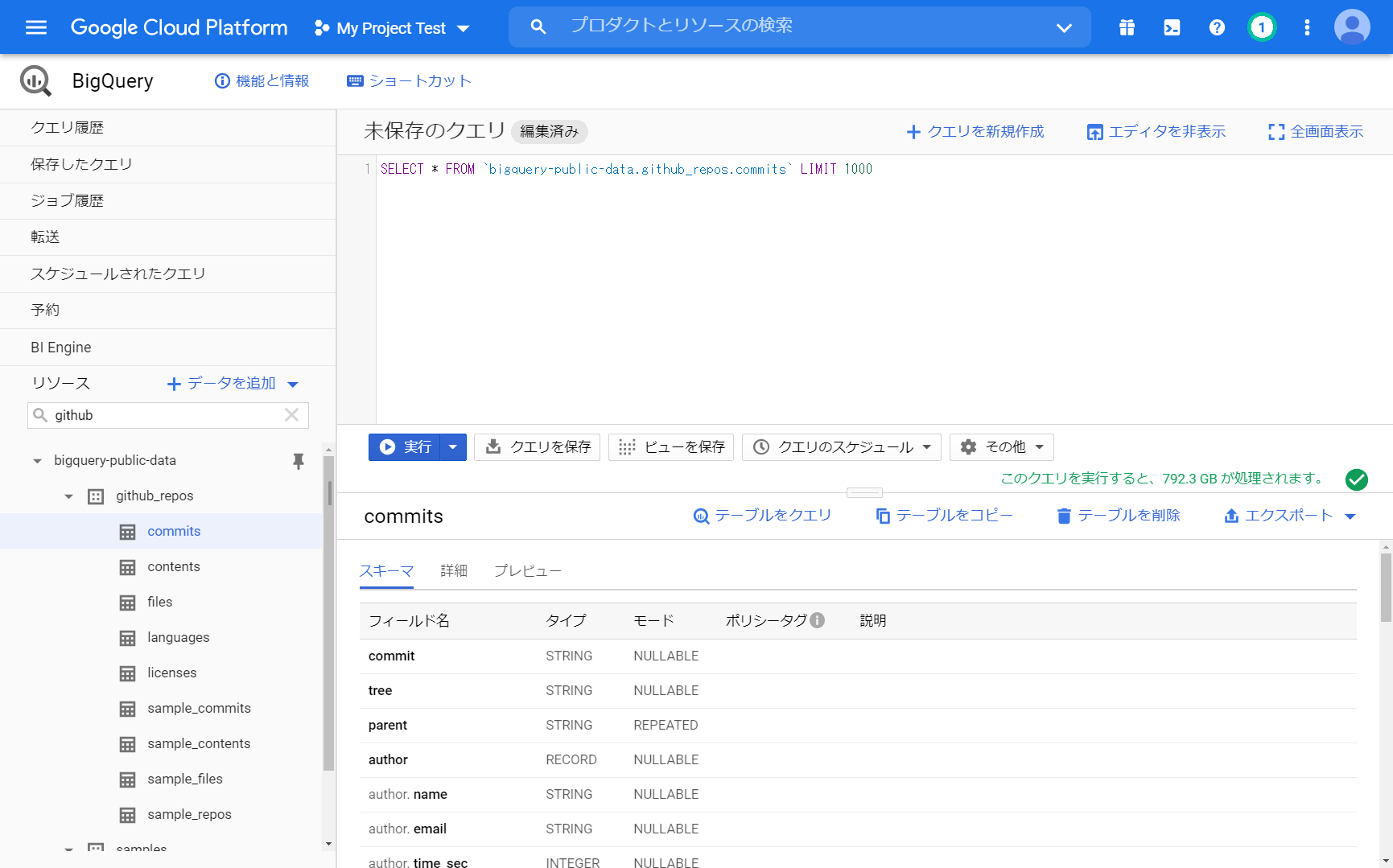
SELECT * を SELECT subject にすると 「10.3 GB が処理されます」になります。
結果として出力する情報量(カラム)によって処理されるサイズが変わります。
BigQueryは、この処理量に対して課金されるので、この処理量が重要になってきます。
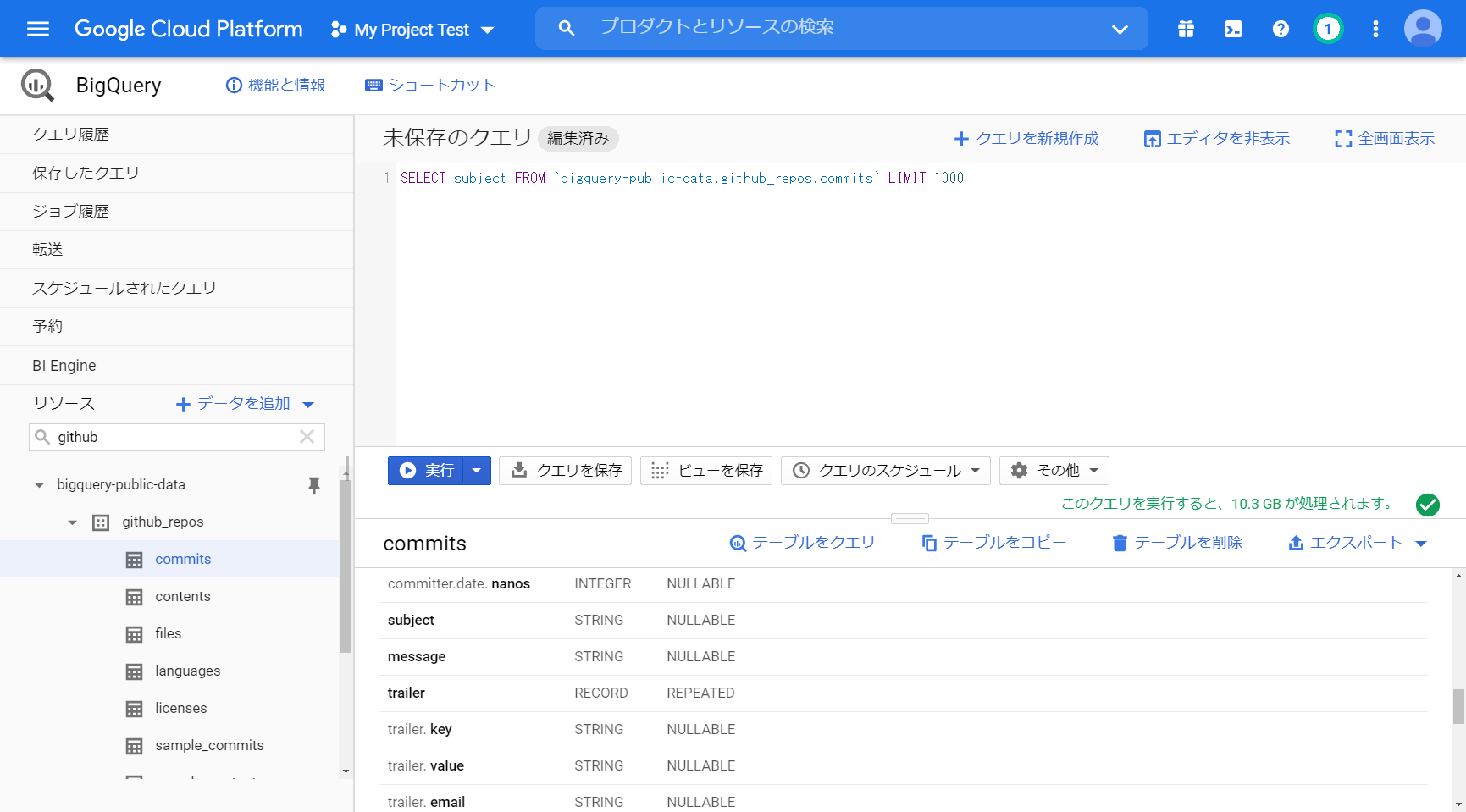
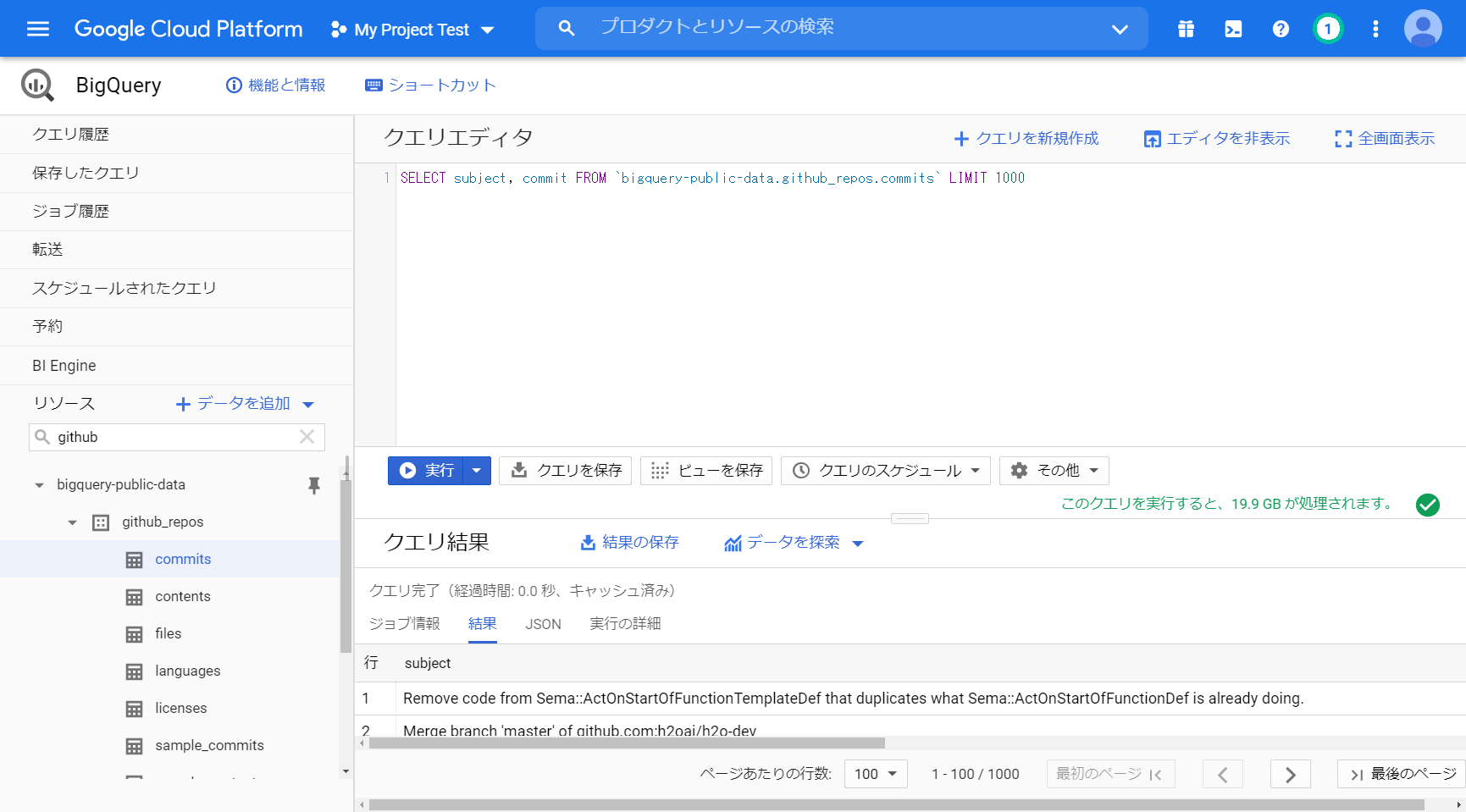
SELECT subjectを SELECT subject ,commit にすると 「19.9 GB が処理されます」になります。
「SELECT subject, commit FROM `bigquery-public-data.github_repos.commits` LIMIT 1000」
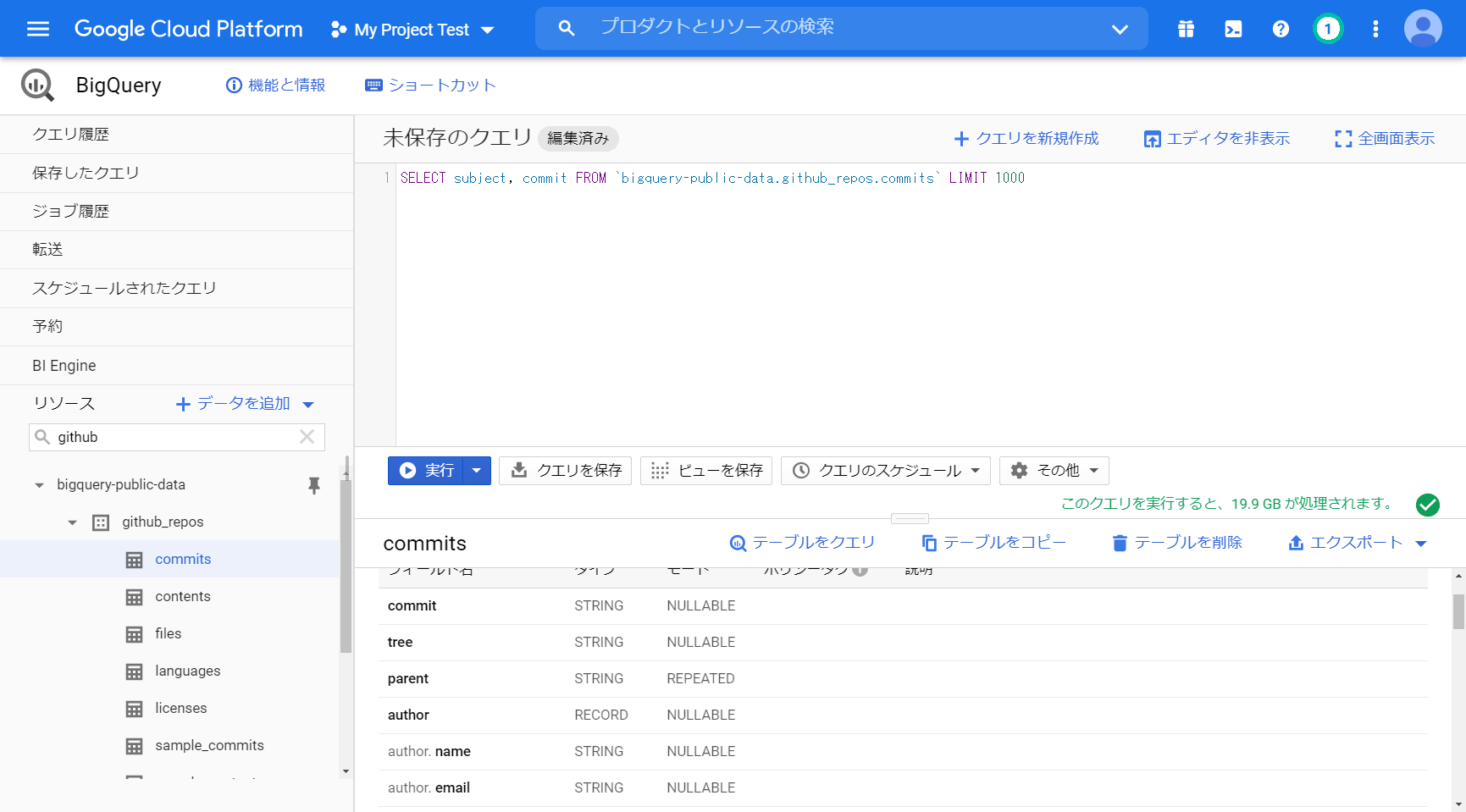
実行すると 0.4秒 で結果が表示されます。
別の日に実行してみたら、1.2秒でしたのでバラツキはあるようです。
空いているマシンリソースを融通して使うので、他のユーザの負荷などに影響を受けそうです。
極端に遅くなることはないと思いますが、SLA(サービス仕様)で性能は担保されていないです。
select *、select カラム名
試しに実行。
「SELECT subject, commit FROM `bigquery-public-data.github_repos.commits` LIMIT 1000」
2億行を 0.6秒で処理
もう一度実行すると、0.0秒です。デフォルトの設定では、検索結果のキャッシュを使うからですね。
キャッシュの詳細については公式サイトの「キャッシュに保存されているクエリ結果を使用する」を参照ください。BigQueryのキャッシュ(公式サイト)
「その他」-「クエリの設定」-“キャッシュされた結果を使用”のチェックを外すと無効にできます。
COUNT
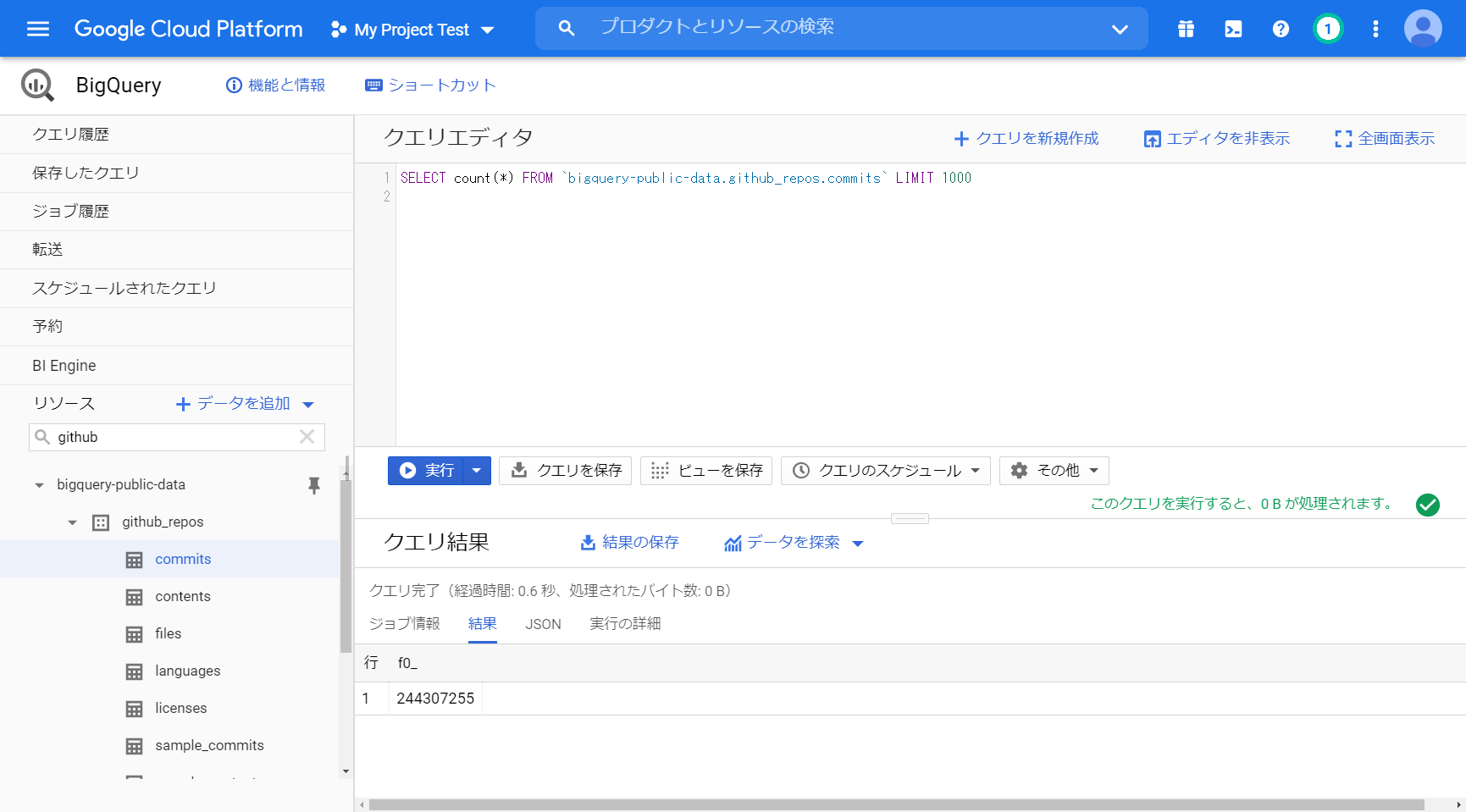
「SELECT count(*) FROM `bigquery-public-data.github_repos.commits` LIMIT 1000」
「このクエリを実行すると、0 B が処理されます。」
0.6秒
これは実行時に全部の行数を数えているのではなく、分散された塊ごとに件数(行数)を覚えていて、合計しているのだと推測。
分散した行数を全部覚えているのであれば、もう少し速いはずで、実行時に行数を数えているのであればもっと時間がかかるはず。
全スキャンと同程度になるはず。
ORDER BY / GROUP BY
グループ化して、降順にソートした場合
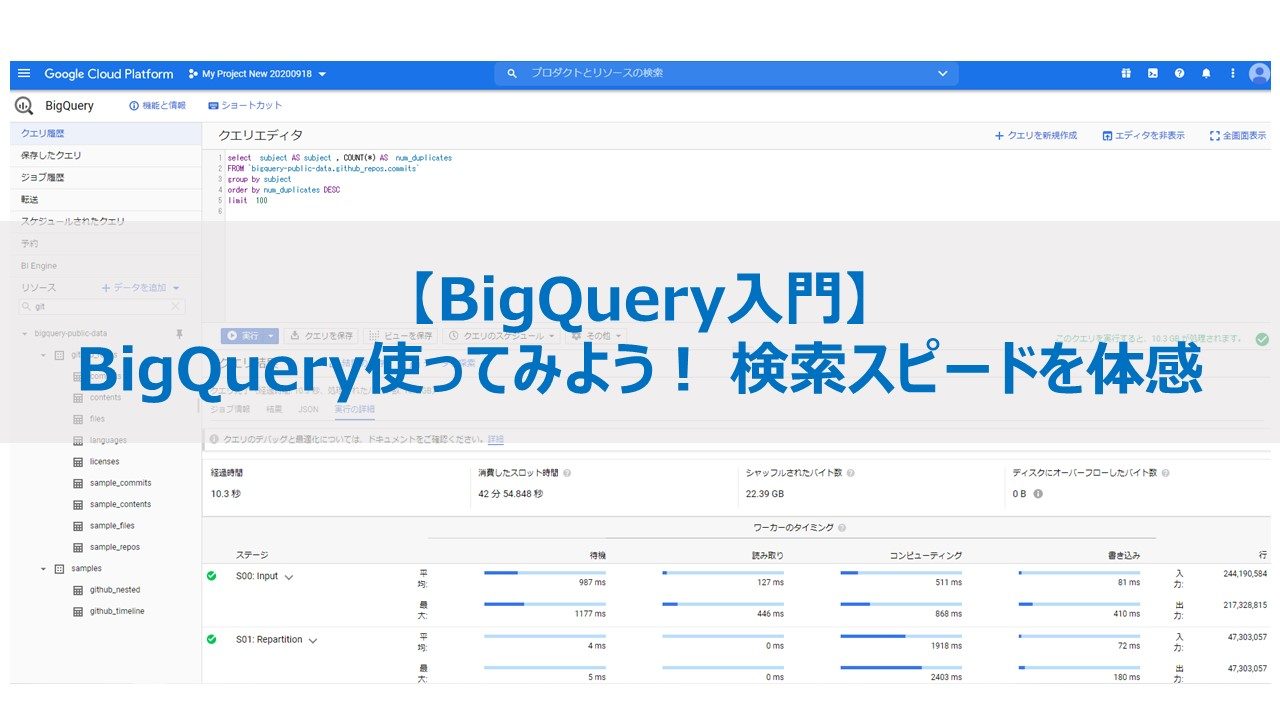
「SELECT subject AS subject, COUNT(*) AS num_dup
FROM `bigquery-public-data.github_repos.commits`
GROUP BY subject ORDER BY num_dup DESC LIMIT 1000」
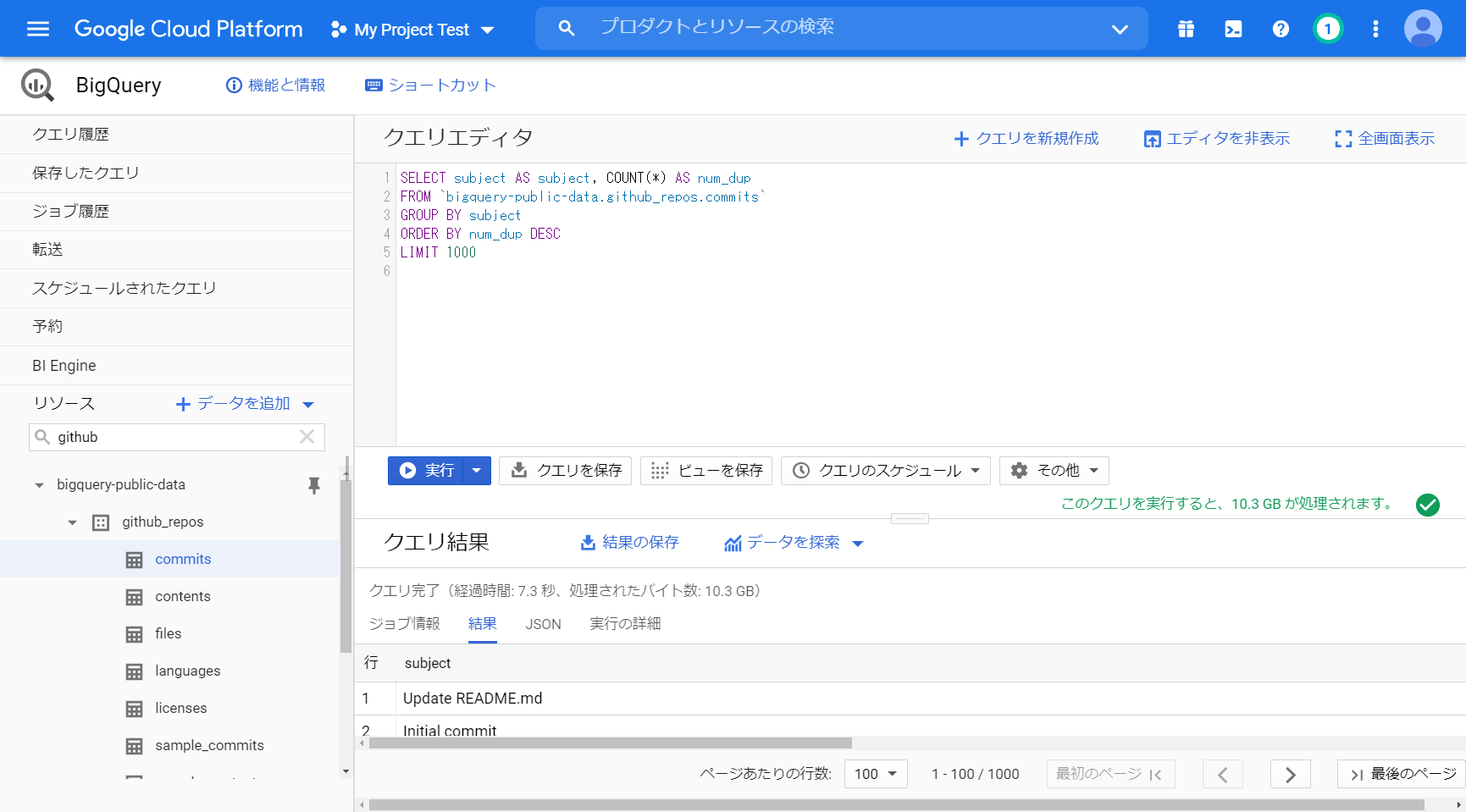
クエリ完了(経過時間: 7.4 秒、処理されたバイト数: 10.3 GB)
今まで比べると少し時間がかかったような感覚になるが、2億行からグループ化し、降順にソートした結果が、7秒はめちゃくちゃ速い。
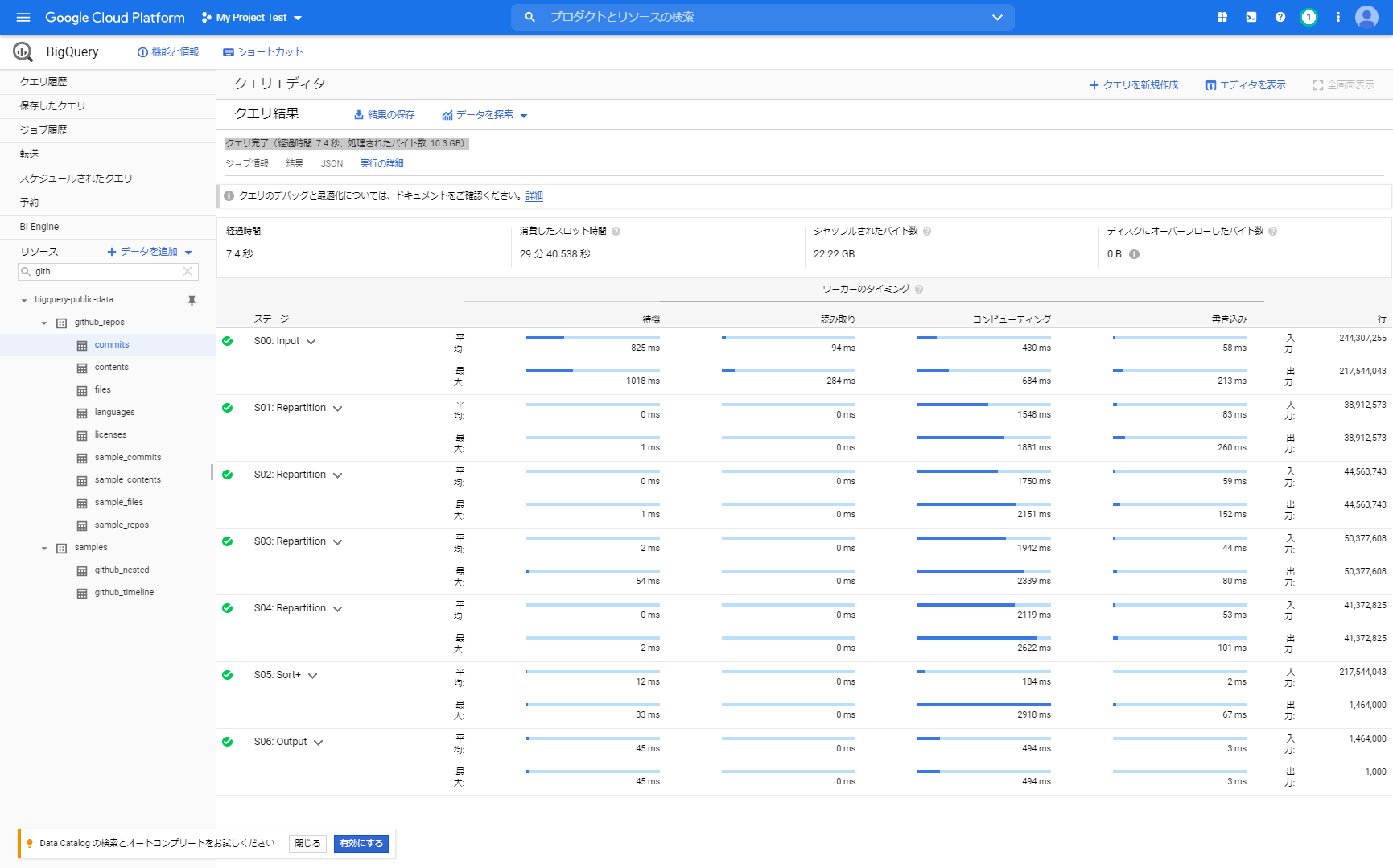
[実行の詳細]を押すと各処理の処理タスクと処理時間が確認できます。
いくつかに分けて(分散して)実行されていることが分かります。
LIKE 部分一致検索
次の検証ではテーブルを変更します。
BigQueryに索引という概念はないので、文字列の一致検索は全スキャンになります。
表 :bigquery-public-data.samples.wikipedia
表のサイズ:35.69 GB
行数 :313,797,035 (3億行)
「SELECT * FROM `bigquery-public-data.samples.wikipedia`
WHERE title LIKE ‘%feed%’ limit 1000 」
クエリ完了(経過時間: 1.4 秒、処理されたバイト数: 35.7 GB)
ヒット件数=27124
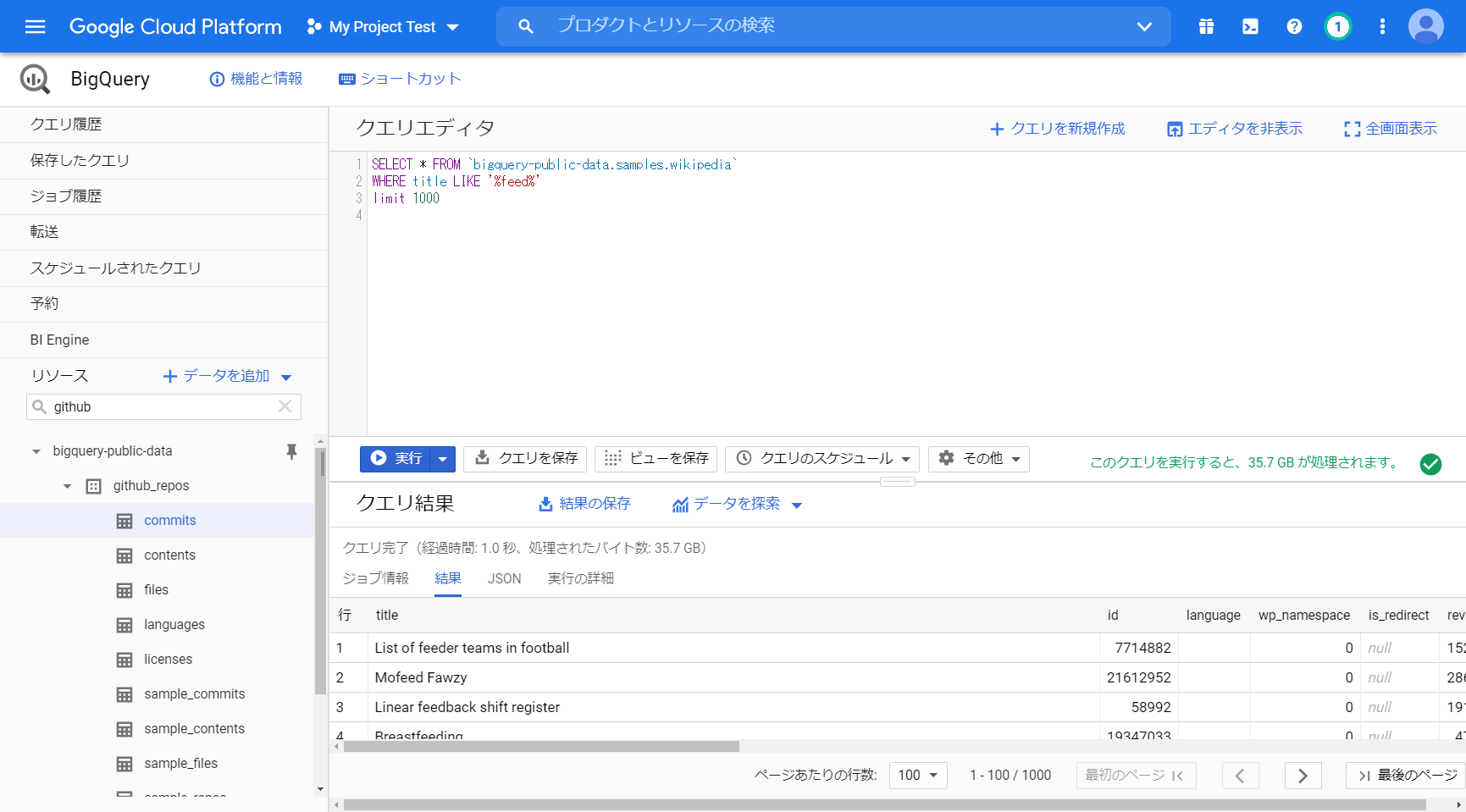
3億件から見つけてくるのに 1.4秒で処理! 爆速!
ヒット件数=27124
完全一致検索も試してみました。
SELECT * FROM `bigquery-public-data.samples.wikipedia`
WHERE title = ‘Linux Mint’
3.2秒 ヒット件数=774
カラムナーの力が十二分に発揮されていますね。
カラム(列)を読むスピードがメチャクチャ速いです。
大まかに試算すると、3億行(300,000,000)でカラムサイズが1つ平均30バイトだとすると読み込みサイズの概算は、900,000,000行 x 10バイト= 9,000,000,000バイト= 9GB
SSDの読込速度が500MB/sぐらいなので、単純に3GBのファイルを読む(read)には、9GB/500MB/s = 18秒かかる。
圧縮してサイズを小さくして速くしてしたりとか、内部で並列実行で速くしているなどありそうです。
「実行の詳細」で処理タスクを見ると今回のケースは分散で読み込むのではないようです。
さらに行数が多くなっても、分散して並列で読み込み可能なら登録行数に比例して遅くなることもないかもしれません。スロットという概念があるので、無尽蔵に並列処理できるわけではありませんが。(スロットの話は、今回は割愛)
巨大テーブル(パーティション)
更に大きなデータで確認するために使うテーブルを変えます。
表 ID : bigquery-public-data:wikipedia.pageviews_2019
表のサイズ : 2.31 TB
行数 : 57,010,621,048 (570億行)
「SELECT * FROM `bigquery-public-data.wikipedia.pageviews_2019` WHERE DATE(datehour) = “2019-09-18” LIMIT 1000」
このクエリを実行すると、6.6 GB が処理されます。 1日分で6.6GBあります。
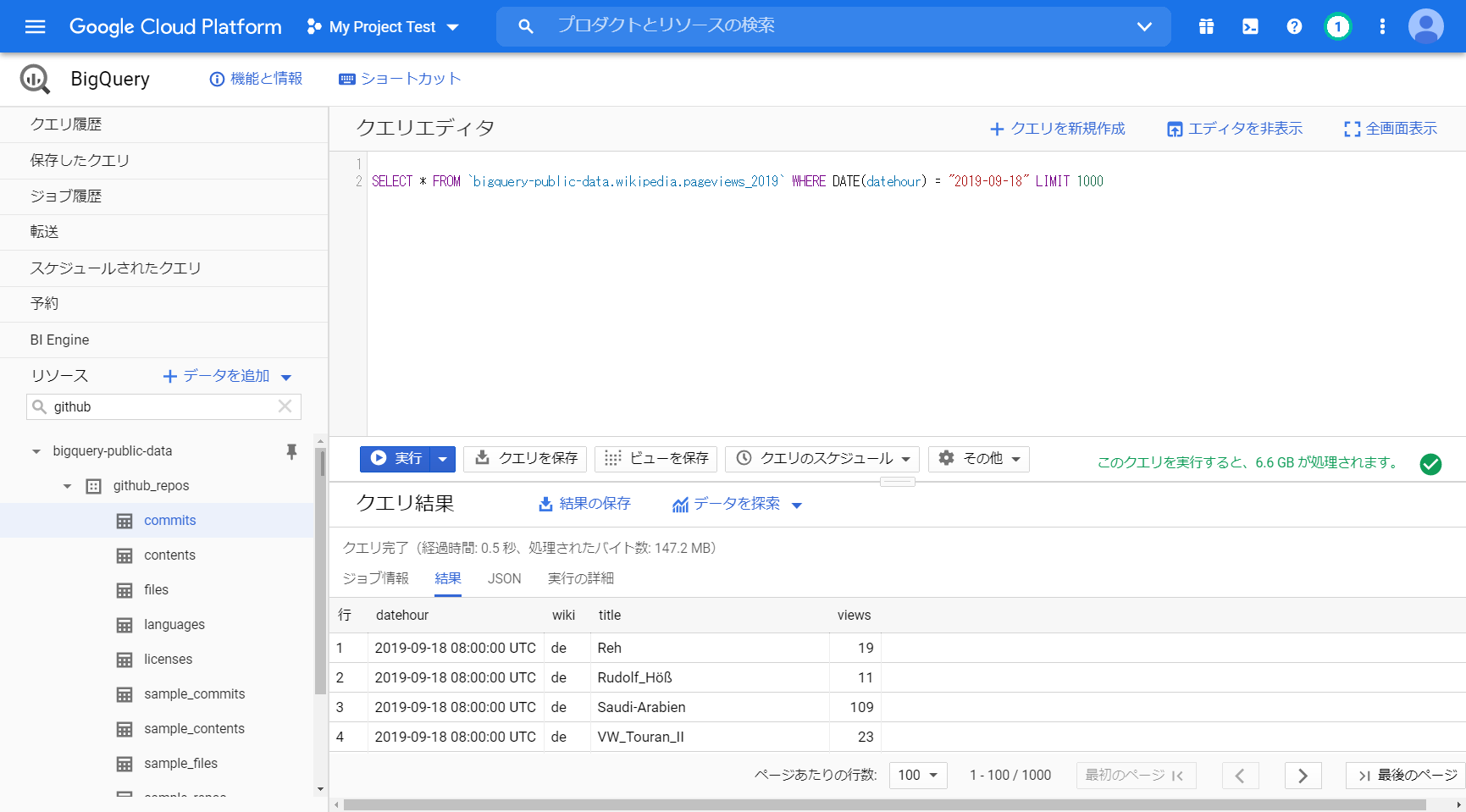
パーティション分割テーブルが使われています。日付で分割されています。
さすがにパーティション分割しないと巨大すぎて、スキャンの範囲を日付で絞らないと性能は出ないか。
このあたりは、きちんと設計しないと期待した性能が出ないですね。
また、全スキャンしていたら料金がバカ高くなります。
<スキーマ構成は以下>
datehour :TIMESTAMP NULLABLE パーティションキー
wiki :STRING NULLABLE
title :STRING NULLABLE
views :INTEGER NULLABLE
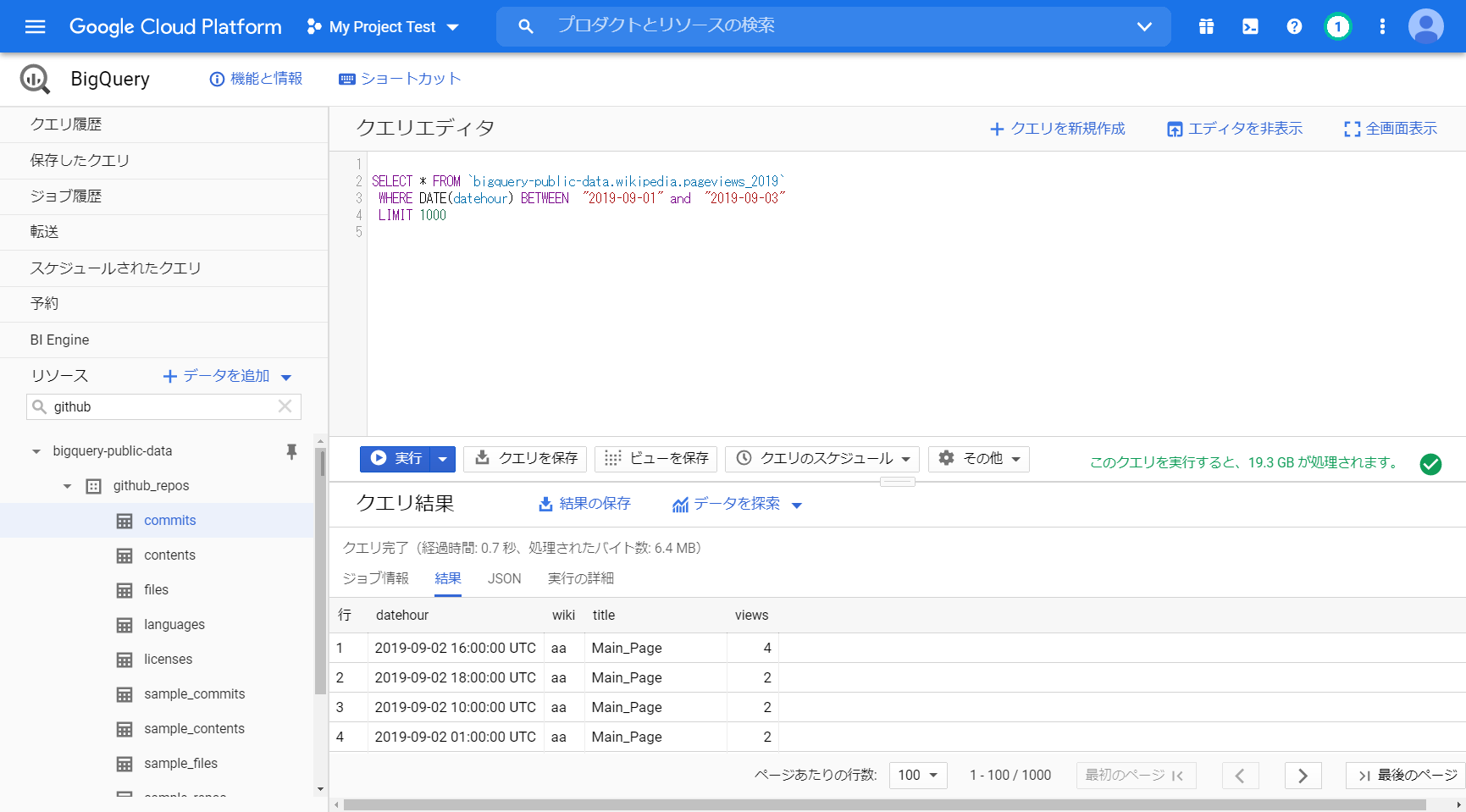
「SELECT * FROM `bigquery-public-data.wikipedia.pageviews_2019`
WHERE DATE(datehour) BETWEEN “2019-09-01” and “2019-09-03”
LIMIT 1000」
クエリ完了(経過時間: 0.6 秒、処理されたバイト数: 268.1 MB)
まとめ
一般公開データセットを利用することにより、簡単にBigQueryの検索性能を体感することができます。
他にもいろいろな種類とサイズのデータがあるので無料で試して、自分の用途に合うかを検証した後に本格活用に切り替えたほうがよいです。
TableauなどのBIツールからも簡単にアクセスできるので、利用シーンはさらに広がりますね。
自分のPCのTableauから、Googleクラウドの中にあるBigQueryにアクセスできます。