自分のPCで生成AIのChatGPTのようなことができたら、楽しいですよね。
ローカルPCで無料で使えるLLMが公開されているので、複数のLLMで生成AIを試してみました。
生成AI、ローカルLLM、LangChainなど知っている人は、一般的な紹介なので、スキップして「ローカルLLMを使うための準備」から読んでもらって構いません。
生成AIとLLMの関係
生成AI(Generative AI)と大規模言語モデル(LLM: Large Language Models)は、密接に関連していますが、それぞれ異なる役割と機能を持っています。
生成AI
生成AIは、データから新しいデータを生成するAI技術の総称です。
この新しいデータは、テキスト、画像、音声、ビデオなど様々な形式を取ることができます。生成AIの代表的な例としては、画像生成モデル(例:DALL-E )、テキスト生成モデル(例:GPTシリーズ)、音楽生成モデルなどが挙げられます。
大規模言語モデル(LLM)
LLMは、特に自然言語処理(NLP)に特化した生成AIの一種です。
LLMは大量のテキストデータを用いて訓練され、人間のような自然な文章を生成する能力を持ちます。GPT-3やGPT-4などのモデルはLLMの一例です。LLMは、以下のようなタスクに使用されます。
・テキスト生成
・質問応答
・言語翻訳
・要約
・対話システム
生成AIとLLMの関係
生成AIは広義の概念であり、LLMはその一部と考えることができます。具体的には、LLMはテキスト生成を行う生成AIの一種です。LLMは、自然言語テキストを理解し、生成するために設計されており、その訓練には大量のテキストデータと高度なディープラーニング技術が用いられます。
まとめると、生成AIは広範なデータ生成技術の総称であり、LLMはその中でも特に自然言語処理に特化したモデルです。両者はAIの進化において重要な役割を果たしており、様々な分野で応用されています。
ローカルLLMとは
ローカルLLM(Large Language Model)は、ユーザーのローカル環境で実行される大規模言語モデル(LLM)のことを指します。
一般的に、LLMは大量のデータと計算リソースを必要とするため、クラウドサービスを利用することが多いですが、ローカルLLMはこれをユーザーの手元のPCや専用サーバーで動かすことが可能です。
大規模言語モデル(LLM: Large Language Models)より、規模からすると、SLM(Small Language Models)の呼び方のほうが合っていますね。
最近はSLMと呼ぶ場合もあるようです。
【ビジネス+ITの記事】小規模言語モデル(SLM)とは? マイクロソフトPhi-3やグーグルGammaは何を競うのか?
ローカルLLMの特徴と利点
1. プライバシーの保護:
ローカル環境で実行するため、データが外部に送信されることがなく、プライバシーが保護されます。
2. カスタマイズ性:
ユーザーが直接モデルにアクセスできるため、特定のタスクやアプリケーションに合わせてカスタマイズしやすいです。
3. オフライン動作:
インターネット接続がなくても使用可能なため、常にクラウド接続が必要ない状況でも利用できます。
4. 遅延の低減:
ローカルで処理が行われるため、応答速度が速くなります。応答速度はマシンとモデルの選定に依存します。
ローカルLLMの課題
1. 計算リソース:
大規模な言語モデルをローカルで動かすには、高性能なハードウェアが必要です。特にGPUが必要になる場合が多いです。
2. ストレージ:
大規模なモデルは大量のストレージを必要とするため、ディスク容量も問題になります。
3. メンテナンス:
モデルのアップデートやメンテナンスをユーザー自身で行う必要があるケースがあります。
主な使用ケース
– エンタープライズ環境:
機密データを取り扱う企業では、データを外部に送信せずにローカルLLMを利用することで、セキュリティを確保しつつ高度な言語処理を行えます。
– エッジコンピューティング:
ネットワークの遅延や帯域幅の制約がある環境で、ローカルデバイス上でモデルを実行し、リアルタイムのデータ処理を行います。
– 個人の使用:
個人の研究や趣味で、特定のタスクに適したモデルを試行錯誤しながら使う場合にも有用です。
ローカルLLMは、特定の要件や制約を持つ環境での応用が期待されており、今後もその重要性は増していくと考えられます。
ローカルLLMの種類
ローカルLLMは、いろいろ公開されています。
Googleが公開している軽量かつ高性能なLLMのGemmnaで特徴をベースに説明します。
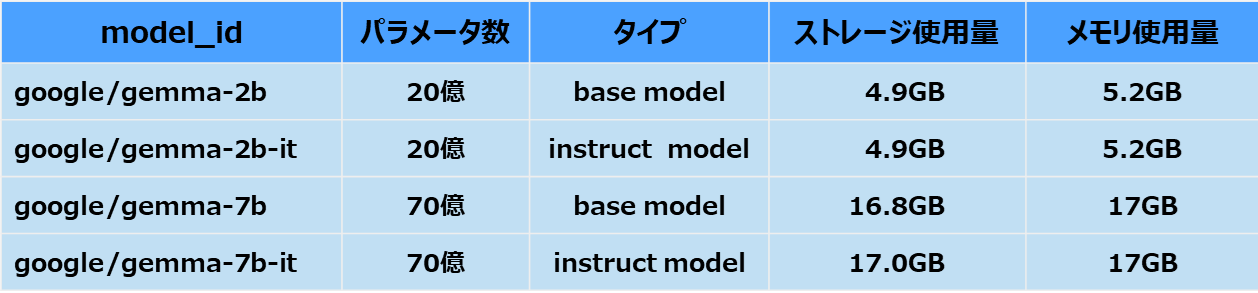
Gemmaのモデルには、20億パラメータの「Gemma 2B」と70億パラメータの「Gemma 7B」があり、それぞれに事前学習済みのbase modelと人間の指示に基づいた回答をするためのinstruction modelが用意されています。
モデル名の 2B,7B, -it はこのあたりのルールで命名されています。
■ローカルLLMのパラメータ数(Google Gemmaの場合)
・パラメータサイズが大きいほどメモリとストレージ容量が必要
・GPUが搭載していないマシンの場合、通常のメインメモリ(RAM)を使って動作可能
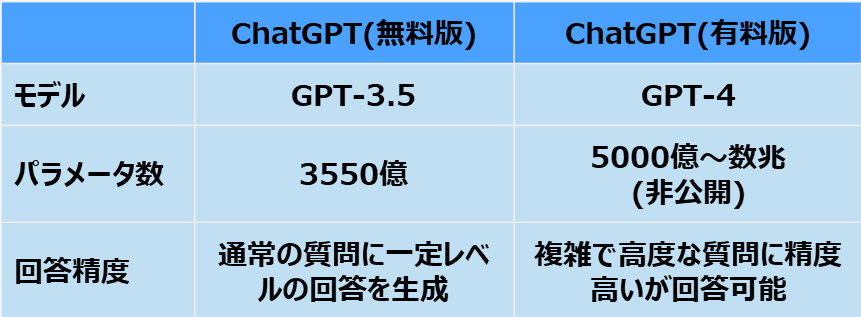
■ChatGPTのパラメータ数
ローカルLLMとGPTのパラメータ数と違います。これは回答の精度に影響を与えます。
各社、少ないパラメータ数で回答の精度を上げる工夫をいろいろやっているので、新しいモデルが毎週のように生まれている状況ですね。
LangChainとは
LangChainは、言語モデルを用いたアプリケーションを作成するためのフレームワークです。
Pythonで利用可能です。
特に、複数の言語モデルやデータソースを組み合わせて高度な自然言語処理(NLP)タスクを実行するために使用されます。以下はLangChainの主な特徴です。
多様なデータソースの統合:
LangChainは、テキスト、画像、音声などの異なるデータソースを統合する機能を提供します。これにより、ユーザーは複数のデータソースを組み合わせて利用できる柔軟なアプリケーションを構築できます。
言語モデルのチェーン化:
名前の通り、LangChainは複数の言語モデルをチェーン(連鎖)させて利用することができます。これにより、複雑なタスクを段階的に処理することが可能になります。例えば、初めにテキストを生成し、その後に生成されたテキストを解析する、といった処理が行えます。
モジュール性:
LangChainはモジュール化されており、ユーザーは必要な機能を選択して組み合わせることができます。これにより、カスタマイズ可能で拡張性の高いアプリケーションを構築できます。
オープンソース:
LangChainはオープンソースプロジェクトであり、コミュニティによる開発と改善が行われています。ユーザーは自由にソースコードを利用、修正、共有することができます。
LangChainを使用することで、自然言語処理のアプリケーション開発が効率化され、より複雑なタスクにも対応できるようになります。
例えば、チャットボット、カスタマーサポート、コンテンツ生成、自動要約などの用途に利用されます。
ローカルLLMを使うための準備
・Pythonの環境を準備(この記事では省略)
・公開されているLLMを使うために、Hugging Faceにユーザ登録
・LangChainのインストール
Hugging Faceでユーザ登録
Hugging Faceは、人工知能(AI)のモデルやデータを共有し、利用するためのオープンソースプラットフォームです。
自然言語処理の分野において特に有名であり、AIの開発者や研究者がモデルを共有し、利用するための主要な場所となっています。
Hugging Faceの主な目的は、AIコミュニティの協力と共有を促進することです。
プラットフォームは、AIモデルやデータセットをユーザーがアップロードし、共有することができるようになっています。
また、他のユーザーがアップロードしたモデルやデータセットを検索して利用することもできます。
Hugging Faceは、AIの開発や研究に役立つさまざまなツールを提供しています。
代表的なものとしては、自然言語の分野で主に活用される「Transformers」ライブラリや、画像や音声を扱う分野に強い「Diffusers」ライブラリ、データセットを簡単に扱うことができる「Datasets」ライブラリ等があります。
Hugging Faceで共有されるモデルやデータセットはこれらのライブラリに基づいており、一大プラットフォームとしての地位を築いています。
これらの特性により、Hugging FaceはAI・機械学習に特化したGitHubと、クラウド実行環境が合わさったようなサービスとも言えます。
LangChainのインストール
Pythonを使用します。
いろいろ将来的にも必要になりそうなライブラリを含めてインストールします。
Ubuntuの場合
リポジトリの更新:
sudo apt update
sudo apt -y upgrade
sudo apt install -y python3-pip
■Windows / Linux共通
pip install huggingface_hub
pip install langchain langchain_community
pip install langchain-cli
pip install transformers accelerate sentencepiece
pip install bitsandbytes
pip install llama-cpp-python[server]
pip install torch
WindowsでPythonプログラムでGPUが使われない場合は以下の記事を参考にしてください。

LLMを使うPythonプログラム
この記事で紹介しているPythonプログラムは、そのまま実行可能です。
LLMを使うプログラムの事前準備
環境によっては、pythonではなくpython3で実行してください。
#python simple-query-llm.py モデル名 出力トークン数
python simple-query-llm.py google/gemma-2b-it 128
python simple-query-llm.py google/gemma-7b-it 128
モデル名は以下のような名前です。xxxx/yyyyyy の形式が多いです。
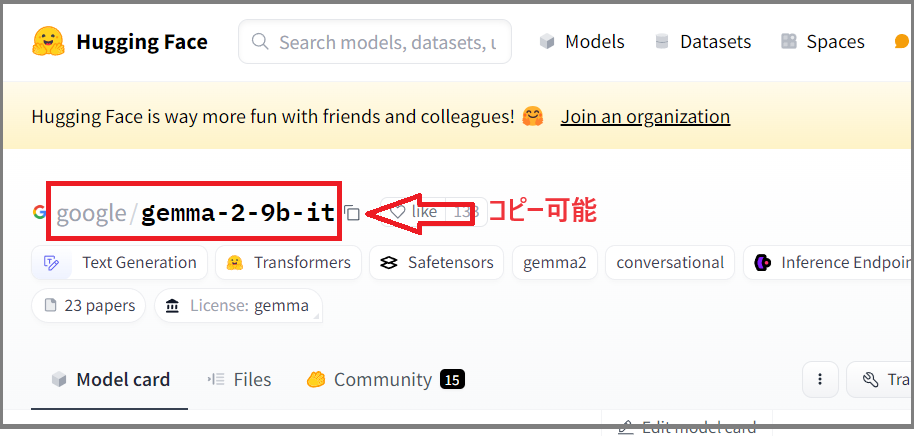
Hugging Faceのユーザ登録だけでなく、モデルによっては事前に使用許諾が必要な場合があります。Google Gemmaは使用許諾のボタンを押す必要があります。
LLMを使うプログラムの説明
ソース python「simple-query-llm.py」
<注意事項>
・Hugging Face のトークンを人に使わせないように。
・一回目はローカルPCにモデル・ファイルをダウンロードするので時間がかかります。
20億パラメータの「Gemma 2B」で5GB、70億パラメータの「Gemma 7B」で17GB。
#!/bin/bash
# python3 simple-query-llm.py モデル名 出力トークン数
# python3 simple-query-llm.py google/gemma-2b-it 128
import datetime
import os
import sys
from transformers import (
AutoTokenizer, AutoModelForCausalLM, pipeline
)
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from langchain_core.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
fmt = '%Y年%m月%d日 %H:%M:%S'
# HuggingFaceのトークンの設定(huggingFaceのモデルを使用するため)
# HuggingFaceで事前にトークンの取得が必要。取得したトークンを設定。
os.environ["HF_TOKEN"] = "<< huggingfaceのトークン >>"
# モデル名を設定
# repo_id = "google/gemma-7b-it"
repo_id = sys.argv[1]
print("(1)" + datetime.datetime.now().strftime(fmt))
# モデルの設定/読み込み 。
# 一回目はローカルにダウンロードで時間がかかる。
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=repo_id,
device_map="auto"
)
print("(2)" + datetime.datetime.now().strftime(fmt))
# トークナイザーの設定
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=repo_id
)
# パイプラインの設定
pipe = pipeline(
"text-generation", # タスクの指定
model=model, # モデルをセット
tokenizer=tokenizer, # トークナイザーをセット
max_new_tokens=int(sys.argv[2]) # 生成するトークンの最大数
)
# HuggingFace Pipeline をLangChain で扱える形式に変換
llm = HuggingFacePipeline(
pipeline=pipe # パイプラインをセット
)
# プロンプトのテンプレート
question_prompt_template_format = tokenizer.apply_chat_template(
conversation = [{"role": "user", "content": "{question}"}],
tokenize=False,
add_generation_prompt=True
)
# プロンプトの設定
QUESTION_PROMPT = PromptTemplate(
template=question_prompt_template_format, input_variables=["question"]
)
# 質問回答のchainの設定
chain = LLMChain(llm=llm, prompt=QUESTION_PROMPT)
# 質問文。日本語も可能。英語でAIについて50wordぐらいで教えて。
question = 'Briefly describe AI in 50 words or so.'
print("(3)” + datetime.datetime.now().strftime(fmt))
# 生成AI(LLM)の回答生成。モデルと質問によって時間がかかる。
response = chain.invoke({“question”: question})
print(“(4)" + datetime.datetime.now().strftime(fmt))
# 回答を出力
print(response["text"])
実行時エラーの回避
実行時に以下のエラーになる場合があります。
ポイントは「requires jinja2>=3.1.0 to be installed. Your version is 3.0.3」の部分です。
Traceback (most recent call last): File "/home/azadminuser/apl/simple-query1-test.py", line 72, in <module> question_prompt_template_format = tokenizer.apply_chat_template( File "/usr/local/lib/python3.10/dist-packages/transformers/tokenization_utils_base.py", line 1817, in apply_chat_template compiled_template = self._compile_jinja_template(chat_template) File "/usr/local/lib/python3.10/dist-packages/transformers/tokenization_utils_base.py", line 1894, in _compile_jinja_template raise ImportError( ImportError: apply_chat_template requires jinja2>=3.1.0 to be installed. Your version is 3.0.3.
jinja2を最新バージョンにアップグレードすることで解決できます。以下のコマンドを実行してください。
pip install –upgrade jinja2
LLMを使う時のポイント
LLMのモデル・ファイルについて
モデルはファイルサイズが大きいので、複数にLLMを使う場合は空き容量にも注意が必要です。
Windows ユーザフォルダ下の “.cache” にモデルファイルがダウンロードされます。
Linuxはホームディレクトリ下の “.cache”ディレクトリにダウンロードされます。
隠しディレクトリになっているので、Linux だと ls -a で -a オプションが必要です。
elyza–Llama-3-ELYZA-JP-8B を使う場合、16GBのファイルがダウンロードされます。
Windowsの場合(“XXX”にはユーザ名が入ります)
C:\Users\XXX\.cache\huggingface\hub\models–elyza–Llama-3-ELYZA-JP-8B\snapshots\e6c316496ee7d9a11710c50229e8cb39b6b0a4a3\

モデルの更新か何かがあると、別ディレクトリにダウンロードされることがあるようです。
このあたりのルールは確認できませんでした。
LLM実行中のリソース使用状況
Linux(Ubuntu)でdstat コマンドを使ってリソースの使用状況を確認。
2回目の実行画面です。(1回目の実行は、モデルファイルのダウンロードが発生します)
上から1秒ごとのリソースの使用状況を確認できます。
GPUなしのマシンなので、CPU処理が100%になります。
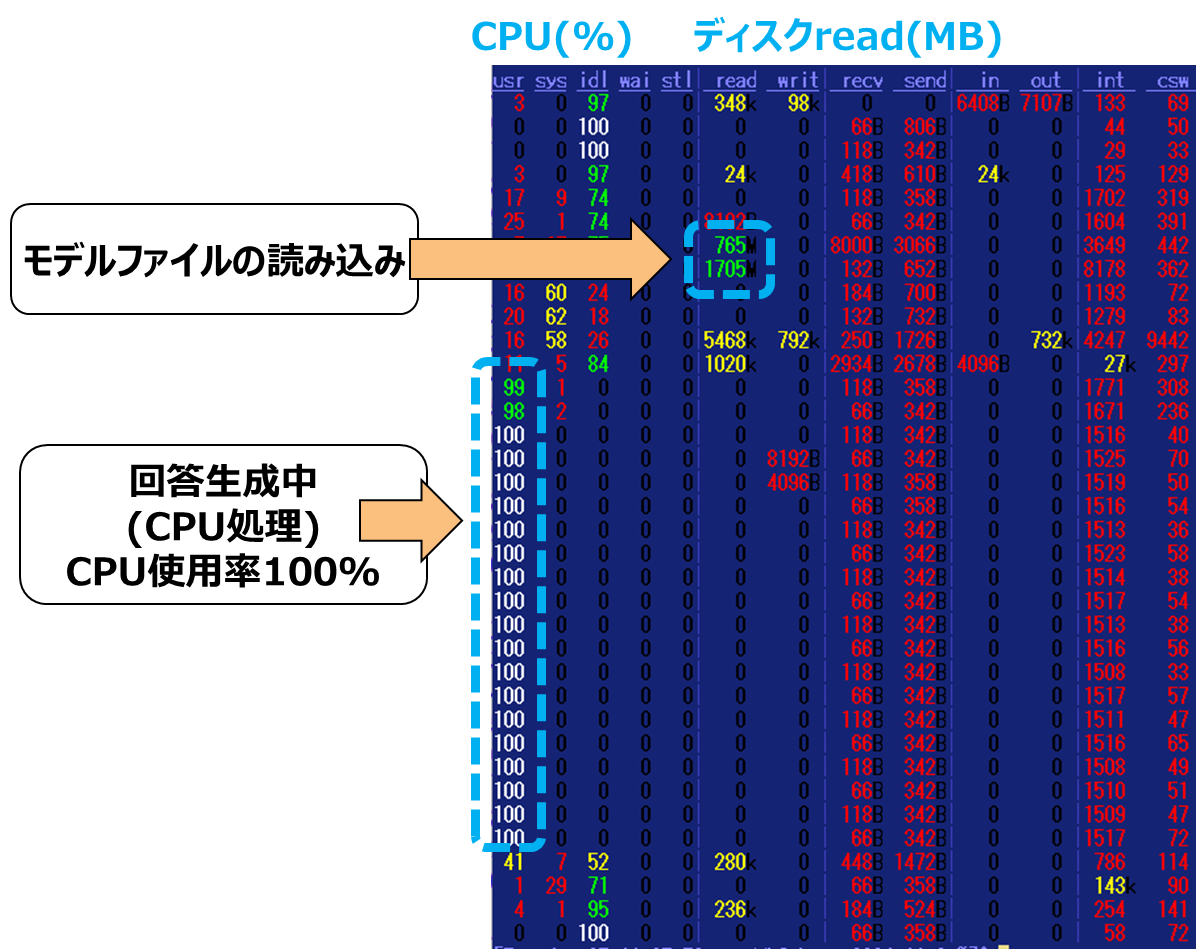
OSのスワップなどが発生している場合は、メモリ不足です。
メモリ不足になるとPythonプログラムで、変なエラーになります。
ちなみにGPUの使用状況は、「nvidia-smi」で概要は分かりそうです。
生成AI(LLM)回答作成の測定
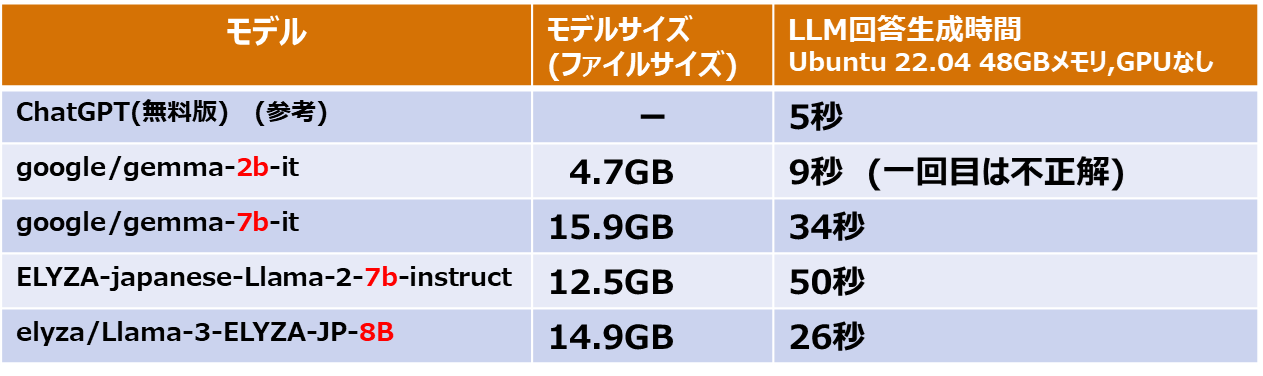
(検証1)LLMの種類で回答生成の速度が違う
上記のPythonプログラム「simple-query-llm.py」を実行して単純な質問で検証。
ブログ記事などで回答の精度を見ることがありますが、LLMごとの実行速度を記載した情報はあまり見かけませんね。結構違うことが分かりました。

・回答速度は質問内容とGPUの有無/メモリサイズなどに依存
・パラメータ数が多いと遅くなる。gemma-2b → gemma-7b
ただし、パラメータ数が多いと難しい問題に回答できるようになるはず。
・モデルサイズをメモリに読み込むので、このサイズ分のメモリは必要。ディスクを併用する方法もありそうですが、遅くなるので実用的な解決方法ではない。
・gemma-2bなどはGPUを使えば高速になると予想していたが、GPUなしサーバ機の負けている。(このあたりは別途解析したい)
(検証2)LLMの種類で回答生成の速度が違う
データの分析の質問をして検証を実施しました。
2024-06-01T00:00:10.000Z , 30
2024-06-01T00:00:20.000Z , 30
2024-06-01T00:00:30.000Z , 50
2024-06-01T00:00:40.000Z , 50
2024-06-01T00:00:50.000Z , 800
2024-06-01T00:00:60.000Z , 60
2024-06-01T00:00:70.000Z , 70
2024-06-01T00:00:80.000Z , 30
・回答の精度(正しさ)を上げるには、パラメータ数が多いモデルの利用が必要になる
・大きいモデルの利用には、より高性能なサーバが必要になる。
・同じパラメータ数(7b)でも応答速度に差がある。gemma-7b とELYZA-7bの性能差 1.5倍
・llama-3 ベースのELYZAのほうが、llma-2 ベースのELYZAより高速
一部表現が不自然だが、gemma-2b-it の1回目以外は正解を回答。
<ChatGPT 無料(GPT-3.5 )> 回答に5秒
「値が通常30〜70の範囲内で推移している中で、突然800という値が記録されています。このような極端に大きい値は異常値と見なすことができます。
従って、2024-06-01T00:00:50.000Z の値 800 は異常値である可能性が高いです。」
<gemma-2b-it > 回答に 9秒
・(1回目):時間 2024-06-01T00:00:30.000Z のデータは、異常値であることが確認されます。 ★不正解
・(2回目):時間と値の組み合わせが、2024-06-01T00:00:50.000Z のデータに異常値があると考えられます。
<gemma-7b-it > 回答に 34秒
・ (1回目):データの異常値は、最後のデータ点(2024-06-01T00:00:50.000Z)の値である800です。他のデータ点の値はすべて30や50の値
・ (2回目):データに異常値は、最後のデータ点(2024-06-01T00:00:50.000Z)の値(800)です。他のデータ点の値はすべて 30~ 50 で
<ELYZA-japanese-Llama-2-7b-instruct> 回答に5分15秒 【極端に遅い】
・ (1回目):データの最後の値は800であり、他の値と比べて大きいため、異常値と判断できます。
・ (2回目):データの最後の値は800であり、他の値と比べて大きいため、異常値と判断できます。
<Llama-3-ELYZA-JP-8B> 回答に26秒
・ (1回目):データの最後の値は800であり、他の値と比べて大きいため、異常値と判断できます。
・ (2回目):異常値は、2024-06-01T00:00:50.000Zの値「800」です。通常の値の範囲が不明ですが、他の値が30~70の範囲内であることから、800は明らかに異常な値と言える。
測定マシン(WindowsとLinux)
以下のマシンで実行。Windows11とUbuntu 22.04で測定。
■HP Victus 16 (2023年11月購入) (PC1)
Windows 11 Home 23H2
CPU:Intel Core i7-13700HX
GPU:NVIDIA GeForce RTX4060 8GB
メモリ(RAM):16GB
Python: 3.12
■サーバマシン (S1)
Ubuntu 22.04 server メモリ48GB、ディスク300GB ,CPU 6コア割り当て(VM上に構築)
CPU:Intel Xeon Silver 4314 2.40GHz
GPU:なし
メモリ(RAM):48GB
Python: 3.12
考察(私見ですが)
GPUがあれば、そこそこ性能が出ると思っていましたが、そうとも言えないです。
メモリ(RAM)も最低でも32GB、できれば64GBは必要ですね。
今後、GPUクラウドサービスを借りて、実験してみようと考えています。
GPUを搭載していないマシンでも、メインメモリ(RAM)が十分あれば、回答生成速度と回答の精度がバランスがいいLLMを使えば、動作は可能と分かりました。
今回検証した4モデルの中では、gemma-7b-itやama-3-ELYZA-JP-8Bあたり。
最後に
毎週のように、小規模LLMがリリースされていますので、ベースにしているLLMや学習方法によってガラッと性能特性が変わりそうですね。
クラウドで使える ConoHa GPUサーバでも試しています。以下の記事をご覧ください。

LLMの確認だけなら、以下のツール(LM Studio)のほうがインストールも簡単でGUI操作で簡単に確認できます。